
On Giant Leaps...
On Giant Leaps...
The Navy's Misappropriation of Levine et al.'s "Ethnic Diversity Deflates Price Bubbles"

Last week, I talked about Task Force One Navy’s (TF1N) “cherry-picking” problem; namely, the report ignores thousands of potentially relevant academic articles and builds its argument in favor of more aggressive diversity and inclusion efforts on the shaky foundation of two, relatively narrow studies. Along the way, I pointed out that the pressures within academia mean that published research is likely to overstate the benefits of diversity while minimizing its costs. As a result, we should approach the findings of peer-reviewed work on diversity and inclusion with a hearty dose of skepticism.
This week, I’m going to explore a different problem with the Navy’s discussion of diversity. As I talked about in the last post, the TF1N supports its argument in favor of more aggressive diversity and inclusion efforts by claiming that “diverse teams are 58 percent more likely than non-diverse teams to accurately assess a situation.” This claims is sourced to a 2014 peer-reviewed study by Levine et al. entitled “Ethnic Diversity Deflates Price Bubbles.”
Importantly, the TF1N is not the only document to reference Levine et al.’s findings on diversity. A brochure published by the Navy’s Office of Inclusion and Diversity repeats this claim from the TF1N:

Here, I’m going to focus on the Navy’s misappropriation of Levine et al.’s study. There are two reasons for dwelling on this. First, as discussed in my previous post, “evidence-based” policymaking is an increasingly popular idea. As the body of social science research expands and becomes more accessible, there’s a natural tendency for policymakers to cite “the research” in arguing for their preferred solutions to social problems. Without good rules for which of the thousands of studies on any given issue to heed and which to ignore, however, there will be a strong temptation to “cherry-pick” or misappropriate the research findings that confirm one’s priors. My hope is that critiquing the use of social science research in this one case will provide a model for thinking about how to do it better in other cases.
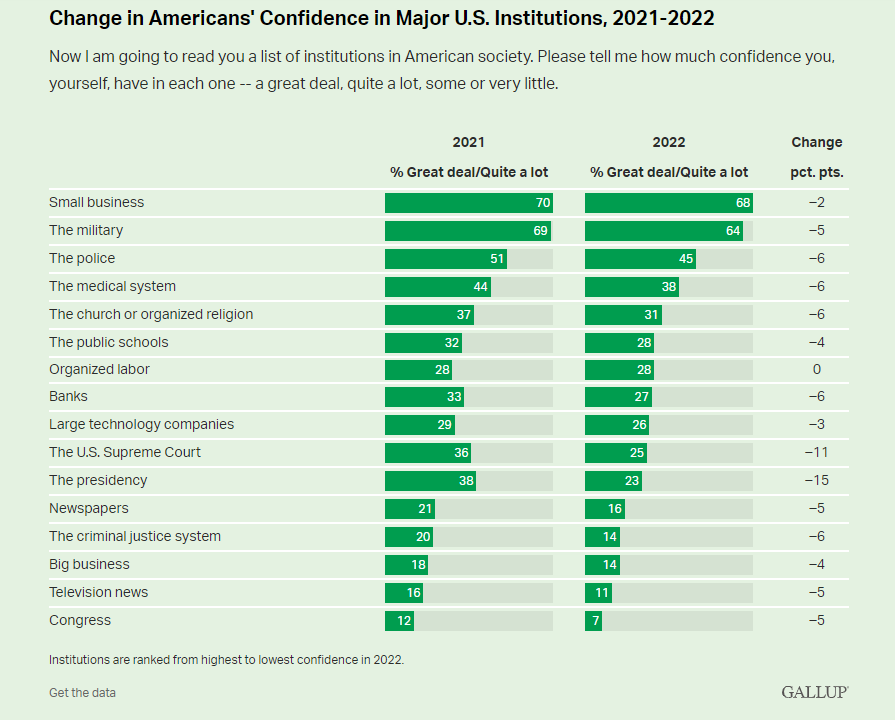
Second, military policy is more important than many other policy areas where social science research might be employed. Making the wrong strategic or tactical decisions in this domain can have catastrophic consequences for American national security. Additionally (and relatedly), bad policy choices at the organizational level might undermine the American public’s trust in the military. Unfortunately, the military is one of the few institutions that Americans still have any confidence in. A recent poll from Gallup found, for example, that the military is the only government-run institution that more than 60% of the public reports having “a great deal” or “quite a lot” of confidence in:
This post (and the last) are an attempt to encourage better policy decisions within the military by pointing out the pitfalls associated with using social science research to guide organizational decisions about diversity and inclusion.
The Two Fundamental Challenges of Social Science Research
There are two fundamental challenges to overcome when producing good social science research: the challenge of internal validity (i.e. persuasively showing that variable X causes the observed changes in variable Y) and the challenge of external validity (i.e. persuasively arguing that variable X will cause variable Y outside of the narrow circumstances used to initially establish that variable X causes variable Y).
Internal and external validity are often in tension with each other and maximizing one often means minimizing the other. Indeed, in order to convincingly demonstrate that variable X is causing changes in variable Y, researchers need to create an artificial situation in which variable X can be systematically increased or decreased while all other potentially influential variables are held constant. The more control researchers exert over their studies, however, the more artificial and, therefore, the less generalizable they become. For example, experiments with very high levels of internal validity frequently fail to replicate despite researchers taking steps to implement the experiments in exactly the same way as the original study (e.g. Deaton 2020; Deaton and Cartwright 2018; Vivalt 2020). It is difficult, in other words, to produce work that is simultaneously causally compelling and broadly applicable.
 student-generated memes from the course...… "")
Academic studies can often make it through the peer-review process despite failing to sufficiently address the challenge of external validity. Academic studies that fail to overcome the challenges of internal validity, however, almost always wind up in a file drawer and not a journal. Put differently, internal validity is valued over external validity in academic publishing and researchers are heavily incentivized to produce work showing evidence of causality even if this evidence is produced under circumstances that have little or nothing to do with life in the “real world.”
The fact that peer review encourages studies to maximize internal validity at the expense of external validity creates a mismatch between the needs of academics striving for publications and policymakers searching for science-based solutions to social problems. Unfortunately, few policymakers seem to acknowledge this mismatch and consider the profound generalizability problems inherent in even the best social science research. Instead, peer-reviewed research is uncritically ported over from academic journals into policymaking documents without any concerns, cautions or caveats. The typical application of research to policymaking goes something like this: “One study found that A causes B in situation C among group D so we should expect that ‘A-like thing’ will cause X in situation Y among group Z.” Policymakers make a “giant leap,” in other words, between the study and the application.
The Ten “Giant Leaps” between the Navy and Levine et al.
So let’s discuss the 10 largest “leaps” the TF1N and the Navy’s Office of Inclusion and Diversity ask us to take by invoking the findings of Levin et al.’s study:
Giant Leap #1 - From Singapore and Kingsville to Everywhere, USA
The results of an experiment should typically be considered generalizable only if they are derived from a sample that is large and representative of the population being generalized to. The Levine et al. study relies on data collected from an experiment conducted on 180 people. In the paper, the authors provide the following discussion of who was included in this sample:
To study the effects of diversity on markets, we created experimental markets in Southeast Asia (study 1) and North America (study 2). We selected those locales purposefully. The ethnic groups in them are distinct and nonoverlapping—Chinese, Malays, and Indians in Southeast Asia, and Whites, Latinos, and African-Americans in North America—thus allowing a broad comparison. We also sought more generalizable results by including participants beyond Western, rich, industrialized, and democratic nations
Digging around in the appendices and supplemental materials for the paper reveals that the study used participants living in only two locations: Singapore and Kingsville, Texas. The 180 participants were not evenly divided between the two research sites. As a table from the paper’s supplemental materials show, only 54 participants (in nine “markets”) were from Kingsville, Texas:
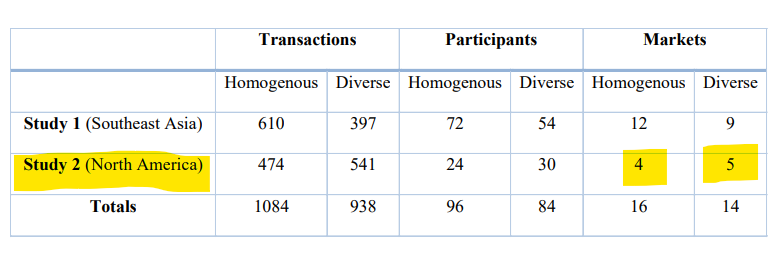
Assuming that diversity will produce the same effects among the entire, geographically varied 330,000 member United States Navy that it did for a few dozen Texans and 126 Singaporeans is one of the many “giant leaps” that the asks us to make.
Giant Leap #2 - From Staff and Students to Officers and Soldiers
The supplemental materials from the Levine et al. paper also disclose that the study “sampled only from university students and staff” living in Singapore and Kingsville, Texas. As the authors explain:
“The participants were recruited in each site using identical email messages and posters, which advertised a ‘stock trading simulation’ where money could be earned.”
All of the volunteers that responded to these recruitment messages were not necessarily included in the study. According to the authors, potential participants were excluded if they were not “trained in business or finance” or if they self-identified with “multiple ethnicities.”
College students looking to earn extra money by participating in economics experiments are different from members of the US Navy in innumerable and, perhaps, immeasurable ways. Age, financial situation, professional aspirations, feelings about one’s country and life experiences are just the tip of a vast iceberg of differences across these groups. The distinct attitudinal, psychological, and dispositional profile of US Navy members should be at the top of our heads as we think about whether a given study will apply to them. Assuming that diversity will produce the same effects among the officers and soldiers who have volunteered to serve their country that it did for a handful of college students and staff is another “giant leap.”
Giant Leap #3 - From Minority-Majority to Majority-Majority
For the Kingsville, Texas portion of the experiment, Levine et al. “created homogeneous markets by including only participants that were Latinos. In diverse markets, we included at least one participant of a numerical minority ethnicity.” In the context of this study, the “minority ethnicity” might have been African American, Asian American or white. The authors, however, never say and they are never explicit about how many “minority ethnicity” members were included in their five “diverse” American trading markets.
As mentioned above, only nine of the study’s 30 overall markets were in Kingsville, Texas. If we assume that each “diverse market” in Kingsville had only one “minority ethnicity” participant, the study may have had a total of 49 Hispanic and 5 non-Hispanic college students in their sample. It is even possible that the study did not include a single white, Asian American or African American participant. Put differently, the study created a highly artificial situation in which a national demographic minority (Hispanics) constituted a huge experimental majority.
A related problem is that the study cannot tell us anything about the amount or ratio of diversity required to begin accruing the “accuracy” benefits described in the paper. Although specific details of market composition are never described, it is possible that only one “minority” member was included in each of the “diverse” markets. Would accuracy in pricing assessments increase or decrease with more “diversity” (e.g. if two or three “minority” members were included in the market instead of one)? Would the presence of more than one kind of racial or ethnic diversity (e.g. one African American, one white, one Asian American instead of just one African American) lead to more or less accuracy in perceptions? The study does not say.
A group composed of all Hispanic college students (in the homogenous market) or of 83% Hispanic college students (in the diverse markets) does not reflect the population of US Navy members in general and is unlikely to reflect the composition of smaller units operating within the Navy. As the TF1N itself reports in the table below, Hispanics make up 18% of enlisted members. Whites and blacks, by contrast, constitute nearly 60% of enlisted members and 19% of enlisted members, respectively.

Assuming that “diversity” (operationalized as a single minority group member) will produce the same effects in majority-majority contexts (i.e. where the national majority ethnicity also constitutes the organizational majority) that it did in a highly artificial minority-majority context (i.e where a national minority makes up a dominant experimental majority) is yet another “giant leap.”
Giant Leap #4 - From a Few Minutes in the Waiting Room with Strangers to a Few Months Training Together with Fellow Soldiers
Participants in Levine et al.’s study were strangers. They were alerted to the racial and ethnic homogeneity or diversity of their market by being asked to sit in a waiting room for a few minutes with other study participants. As the study’s authors explain:
“While waiting, participants were allowed to speak with one another and had many opportunities to perceive others’ ethnicity, a categorization process that is typically automatic and highly accurate. Once six participants arrived, an experimenter assigned them to separate cubicles, each of which was equipped with a networked computer.
The study makes no attempt to distinguish the effects that diversity might exert on the decision-making of complete strangers who share nothing in common other than their ethnicity and the effects that diversity might exert on the decision-making of people who share some common, non-ethnic set of identities, experiences, or responsibilities. This distinction is important because, according to Levine et al., the benefits of diversity are a direct and exclusive consequence of the distrust that diversity produces among strangers. In their words:
“Ethnic diversity was valuable not necessarily because minority traders contributed unique information or skills, but their mere presence changed the tenor of decision making among all traders…Diversity facilitates friction. In markets, this friction can disrupt conformity, interrupt taken-for-granted routines, and prevent herding. The presence of more than one ethnicity fosters greater scrutiny and more deliberate thinking, which can lead to better outcomes.”
There is a considerable body of research suggesting that shared experiences, mutual dependence, and the formation of superordinate identities can reduce friction between members of distinct groups. Presumably, this reduced friction would also reduce the benefits of diversity indicated by the study. Given that members of the US Navy are not complete strangers who share nothing in common other than their ethnicity, we should be cautious about taking another “giant leap” in believing that more diversity in the Navy lead to more “accurate assessments” among members of the Navy.
Giant Leap #5 - From Individuals to Teams
After having a chance to observe the racial and ethnic composition of the group, participants were isolated from each other. While “trading” during the experiment, “participants could not see each other or communicate directly.” The experimental context, in other words, was highly individualized and decisions about how to act were made alone and in the absence of any interpersonal communication.
The TF1N ignores this crucial feature of Levine et al.’s experimental design and, instead, claims that the findings of their study show that “diverse teams are 58 percent more likely than non-diverse teams to accurately assess a situation.” It should go without saying that group-based information-processing and decision-making operates according to fundamentally different dynamics than individual information-processing and decision-making.

Consider Solomon Asch’s famous conformity experiments (pictured above). When left alone to determine which lines matched in length, experimental subjects reported the correct answer in more than 99% of cases. When ask to make the same identification in the context of a group giving incorrect answers, however, 37% of respondents gave an incorrect answer in order to conform to the rest of the group. Taking a finding about how individuals make decisions in artificially sequestered environments and claiming that it reveals something about how “teams” process information is yet another “giant leap” in the TF1N report and the Navy’s Office of Inclusion and Diversity brochure.
Giant Leap #6 - From Perfect Information to Imperfect Information
“Perfect information” is a condition in which all consumers and producers in a given market have complete and instantaneous knowledge of all market prices, their own utility, and own cost functions. The experiment created a “perfect” information environment for its participants. As the authors explain:
“participants observed all of the trading activity on their computer screens. They saw the prices at which others bid to buy and asked to sell. They saw what others ultimately paid and received.
Additionally, every participant was provided with all of the necessary information for how to maximize the amount of money they could earn in this market. Specifically, the following directions were given to the participants:

Needless to say, “perfect” information of the kind provided in this experiment almost never exists in the real world. More importantly for our purposes here, this kind of informational environment almost certainly does not exist in the context of military affairs. Given that members of the Navy are most likely to be forced into decision-making under conditions of “imperfect” information (i.e. situations where they do not know what other actors have done and may not even know what the goals of the other actors are), we should be skeptical about making the “giant leap” encouraged by the TF1N and the Navy’s Office of Inclusion and Diversity .
Giant Leap #7 - From Anonymous to Attributable
None of the information received by participants in the experiment was attributed to a specific individual. The authors write, “As in modern stock markets, they did not know which trader made a certain bid or offer.” It would also be possible, therefore, for participants to also infer that other members of the market would not be able to identify their bids and offers.
Deliberation and decision-making in most organizational contexts, including the Navy, are rarely (if ever) anonymous. Instead, people make arguments and issue orders. Those arguments and orders are considered in light of various characteristics of the source (such as the source’s race, gender, likability, trustworthiness, credibility, and integrity). Applying what we learn from anonymous decision-making to an environment in which decision-making is directly attributed to particular individuals is just one more “giant leap.”
Giant Leap #8 - From Money to Meaning
Money was the sole incentive provided to participants in the experiment. As the authors told each participant at the start of the experiment, “If you follow the instructions carefully and make good decisions, you will earn a considerable amount of money. It will be paid to you in cash at the end of the experiment.” While some of the participants may have volunteered for the experiment in order to have an interesting experience, the primary factor for nearly every subject was likely money.
The reasons that someone joins the military are, of course, many and varied. A small RAND Corporation survey of 81 US Army soldiers in 2018 suggested that the choice to enlist is often influenced by two overlapping factors: “institutional” ones like family, honor and duty, and “occupational” ones like benefits, professional development and job stability. The specific breakdown of responses from the survey (which were not mutually exclusive) is presented below:

The RAND study was small, unrepresentative, and focused on the Army (not the Navy). It does alert us, however, to the fact that the decision to enlist in any branch of the armed forces is likely shaped by a complex multitude of factors, including both money and a sense of meaning. Once again, therefore, the TF1N and the Navy’s Office of Inclusion and Diversity expect us to make a “giant leap” between those participating in the experiment (motivated by a small amount of money) and those serving in the Navy (motivated by money, professional development, family history, and a “call to serve”).
Giant Leap #9 - From Competition to Cooperation
Levine et al.’s experiment sets up zero-sum competition between its participants by creating a simulated stock market (i.e. an individual participant earns more money only by taking money from another participant in the form of relatively beneficial asset “trades”).
The fact that participants are motivated by monetary considerations and that their individual financial incentives are structured around a zero-sum competition makes the experimental context a poor analog for the Navy. Members of the Navy are far more likely to view their work in the Navy as one of mutual interdependence and necessary cooperation rather than as zero-sum competition. In short, it is a “giant leap” to assume that the experiment conducted by Levine et al. places people in a situation that can be easily analogized to the Navy.
Giant Leap #10 - From Accurately Assessing Fake Stock Prices to Accurately Assessing All “Situations”
Levine et al.’s study was exclusively concerned with pricing accuracy in fake stock market trades. Specifically, the authors:
“used the prices in which stocks were bought and sold to calculate the ex-post pricing accuracy: the extent to which market prices, on average, approximated the true values of the stocks.” Comparing the homogenous markets (where all six members were from the majority ethnic group) and the diverse markets (where at least one member was from a minority ethnic group), they find that “market prices fit true values 58% better in diverse markets.”
As suggested above, the TF1N and the Navy’s Office of Inclusion and Diversity would like these findings to mean that diversity produces more “accurate assessments” across all “situations” and not just about fake stock prices. Price assessments, however, are likely to be a poor analog for many of the kinds of assessments the Navy would like to maximize accuracy with respect to. Needless to say, it is a “giant leap” from the particulars of Levine et al.’s study (i.e. fake stock prices) to the generals of Navy service.
Summary
What all of this “leaping” adds up to in terms of applying Levine et al.’s study’s findings to the Navy is anyone’s guess. The safest bet, however, is to say that increased diversity efforts will not produce the 58 percent improvement advertised by the TF1N and the Navy’s Office of Inclusion and Diversity. Null effects, of course, are one danger. We might end up spending a great deal of time, energy, and resources on diversity and inclusion efforts that have no payoff at all. A larger danger, however, is that the effects actually push outcomes in exactly the opposite direction that we expected or intended. There are many situations I would be comfortable extending Levine et al.’s findings to. The Navy is just not one of them.
I want to be very clear at the close that nothing I’m saying here should be interpreted as a criticism of what Levine and his collaborators have done. They are academics and, as such, their job is to produce research that can make it through the peer-review process (contributing along the way to a body of knowledge about the issues that they care about). It is clear from reading their study that they are most interested in making strong causal arguments related to individual-level market behavior (i.e. they are most interested in maximizing internal validity). I can find nothing that indicates they have an interest in reaching conclusions that will inform organizational procedures within the military. In fact, Levine et al. deserve credit for being exceptionally clear about the relatively limited contexts where their findings should apply. In other words, the problems described above are entirely a consequence of the misappropriation of Levine et al.’s work by the authors of the TF1N and the members of the Navy’s Office of Inclusion and Diversity.
In this way, the Navy’s use of Levine et al.’s study presents an interesting and under-discussed problem. There is a small but active group of science reformers focusing much-needed critical attention on bad social science research. One hope of these reformers is that publicly voiced criticism will prevent bad studies from leaking out of academia’s ivory tower and into the world of policymaking. For example, psychologist Stuart Ritchie publishes a newsletter about “fraud, bias, negligence and hype in scientific research.” His most recent post dismantles a recent study published in Social Psychology Quarterly that argues racism influences the way that people chose which dogs to adopt from a dog shelter. It’s hard to imagine this study receiving much traction in policymaking after reading Ritchie’s critique. Similarly, social psychologist Lee Jussim’s newsletter (entitled “Unsafe Science”) frequently “debunks” bad social science studies. His latest post picks apart a recently published article on an inappropriately measured and labeled concept called the “Glass Ceiling Index.” Nipping the influence of these studies in the bud by exposing their flaws is one way to (hopefully) ground our policy decisions in better data.
Levine et al.’s work, however, is not like the studies that Ritchie, Jussim, and others most frequently target in their writing. The experimental design is appropriate for the questions being asked, the data analysis is carefully executed, the study’s raw materials are publicly available, and the authors are consistently explicit about the boundaries and limitations of their findings. The problem is that the Navy has asked Levine et al.’s findings to answer questions Levine et al.’s study never even asks in the first place. More attention should be directed at identifying instances of misappropriation like this.